I've been working with Azure Cosmos Db since it still was called Document Db. However, being an integration consultant it never was a real focus area, but on my current contract it's one of the main components of the backend. Starting from scratch, all the way to go-live, I've learned a lot and also found out a few decisions will make or break your solution.
In this blog post I'd like to share what I've learned.
In our landscape we have a couple of domain services, all having their own Cosmos Db instance for storage. The domain services execute the regular CRUD operations against the database. Next to that we have a couple processes to perform async operations on the data, like change (data) feeds to act on changes in the database. The Cosmos Db instances are at the heart of the platform, we use a multi-region write configuration to achieve high availability.
Like the promise of the cloud: we want to be able to run a high performing and reliable solution, at minimal cost.
During the project we came across decision about partitioning, capacity and way of accessing data. I'd like to discuss these topics in this blog, together with monitoring your Cosmos Db instances to determine it's health.
Partitioning
One of the first things you will need to make a decision on when starting with Cosmos Db, is the partitioning question. There is a lot of documentation on partitioning but not everything is easy to understand.
Although I realize there is much more behind partitions, I'd like to give it a try to explain the parts that had most impact.
In Cosmos Db you have two kinds of partitions:
- physical partitions
- logical partitions
Physical partitions
A physical partition is a block on a disk, where the data physically is stored. These partitions are handled by the Cosmos Db service and there is hardly anything you can do to influence it. Microsoft determines where, what and how the data is stored.
A physical partition has a couple of limits defined here. The most important ones are:
- Max 10k RU/s capacity
- Max 20 Gb data
I'll come back to capacity in more detail in one of the next sections, but it's a metric on the number of requests your Cosmos Db instance can handle. It's also a scaling metric and if your application needs more than 10k RU/s capacity, then one physical partition is no longer able to handle that. I'll also come back the consequences when that occurs.
The other hard limit is the size of the data. When it grows beyond 20 Gb, it will also ‘overflow’ to a new physical partition. If you store JSON documents in Cosmos Db then 20 Gb of text is already quite a lot, but in principle the storage is infinite on Azure side, but it has impact on your solution if you have many partitions.
Logical partitions
There are no such limits on logical partitions. Based on your decisions the Cosmos Db service will put one or more logical partitions on a physical one. It's up to Microsoft what to put where, and this happens transparantly to the application.
A Cosmos Db account can contain one or more databases, and one database can contain one or more containers (containers used to be called ‘collections’ and you'll still find that term in the docs every now an then). When you create a container, you have to specify a partition key. This key is a field in your data/document which determines in the end in which logical partition the data will end up.
This is a screenshot of the create container dialog, with the partition key section highlighted.
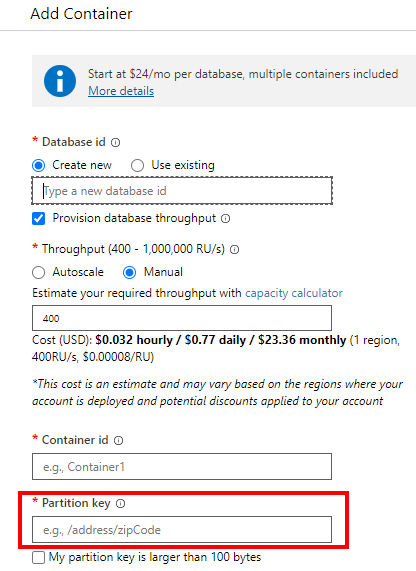
What is the impact of chosing a certain partition key?
Cosmos Db stores the data based on partition key and uses the partition key to lookup the document when you request it. What that means can best be demonstrated based on an example.
If you have a database storing user profiles, then you can decide to use the country of residence as partition key. This means that looking up documents by country will be fast, because all documents for a certain country are in the same logical partition. However, this approach can lead to so called hot partitions. Hot partitions happen when the chosen partition key leads to unbalanced load in logical partitions. If you have customers from around the globe, but most of your customers are only from a few countries, you get hot partitions. Most of the queries/reads will be fired at one of the crowded partitions, and that will lead to latency.
Alternatively, and recommended by Microsoft, you can have as many unique partition key values as possible. You can think of for example a UserId, concatenated ID or some other GUID like value. With this approach you get loads of logical partitions, thereby avoiding hot partitions and looking up documents by the partition key will be fast. It's not a problem to have so many logical partitions and it will improve the overall performance.
We decided to use a single GUID so we'd get an evenly balanced distribution across logical partitions. This value also uniquely identifies a record in our database, and we do a lot of lookups by that value as it uniquely identifies a user.
Provisioning capacity
As mentioned in the previous chapter, the capacity is about the number of requests your Cosmos Db instance can handle, before throttling occurs (famous HTTP 429 response). Capacity can be defined both on database and container level. If you specify it on database level, it is used to power all containers in that database.
This is a screenshot of the create database dialog, with the capacity section highlighted.
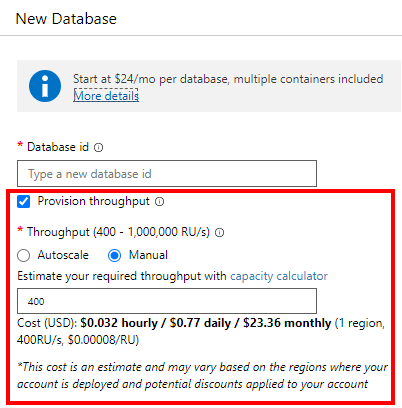
Capacity is defined as number of RU, or Request Units per second. One RU does not mean a single request, it's a calculation of the load a certain request will put on the database. For example a read-by-id (so called point read) is less expensive than a document update. In the Azure portal you can find the Data Explorer tool, which shows you how many RU a certain request consumes.
This is a screenshot of the Data Explorer. The ‘Query Stats’ section will show you the consumed RU and other query related details.
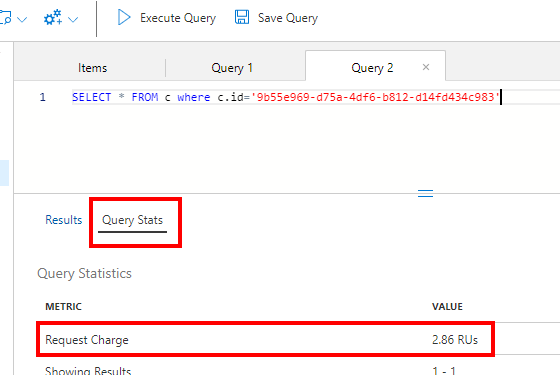
As mentioned earlier, an RU doesn't represent a single request, but involves a calculation using type of operation (read, query, update, delete), document size, number of (write) regions and others. To give you an idea and estimate the number of RU you can use this calculator, which gives a rather good insight in what you can expect. Better would be to execute a representative load test on the Cosmos Db instance, to see whether provisioned capacity is sufficient.
Next to number of RU, you have to decide to use manual or auto scaling.
With manual scaling you get a fixed and predictable capacity and pricing, but are not prepared for unforeseen load. The minimum number of RU you need to specify is 400, but you can increase that value later on. Actually, you can also switch from manual to auto scaling at any time.
Auto scaling is what makes the cloud so great: you define a bandwidth of the necessary capacity. As long as the number of RU you ask from Cosmos Db is within that bandwidth, you're good and you'll pay for the consumed amount (not the reserved max capacity). There is a factor 10 between lower and upper bounds, with a minimum of 400 RU/s, so minimum max RU to define for auto scaling is 4000 per second (meaning a 400-4000 bandwidth). As always, it's important to test adjusting the max RU on a dev/test instance.
In our project we have configured auto scaling on every Cosmos Db instance, with the max of 4000 RU/s. However I can imagine to configure a fixed value of 400 RU/s for your dev/test environment, to minimize the costs and when throttling is not an issue.
Impact on partitions
You might remember I mentioned RU in the chapter about physical partitions and I'd like to explain what the impact of a growing demand for RU has on physical partitions.
The maximum number of RU for a single physical partition is 10k, so what happens when you need more capacity than that? The simple answer to that question is: Cosmos Db will perform a partition split and you'll get a second physical partition.
One of the consequences you need to be aware of is the number of provisioned RU will be evenly assigned across the physical partitions. This means that if you decide to increase the capacity from 10k RU to 11k RU (+10%), because you found out 10k RU was not sufficient anymore, then both partitions will get 5500 RU assigned. If 10k RU was not enough anymore for a partition, then probably 5500 RU is also not enough and that's where the problems start. You have to be very careful with increasing the max RU for a database and you have to be aware of this consequence when increasing the number of RU across a 10k boundary.
Another thing you have to keep in mind, is that you cannot delete partitions anymore once the're created. So if you scale to max 50k RU you will get 5 partitions with 10k RU per partition. If you then scale back to max 20k RU, you will still have 5 partitions, but now with only 4k RU per partition. This could lead to serious capacity issues, which will be visible by a lot of HTTP 429 responses. The only way to get rid of partitions, is to delete the database and recreate it.
In the Classic Metrics you can find standard graphs showing the number of partitions, and whether the capacity is sufficient. In the example below there is 60k RU provisioned, which lead to 6 partitions being created. As you can see in the green HTTP 429 graph, the capacity is at a certain point barely enough. This kind of throttling doesn't need to be an issue though, as your code should be equipped with retries to handle these cases. It will become a problem when the retries lead to even more load leading to thus more throttling, so always use an exponential backoff strategy.
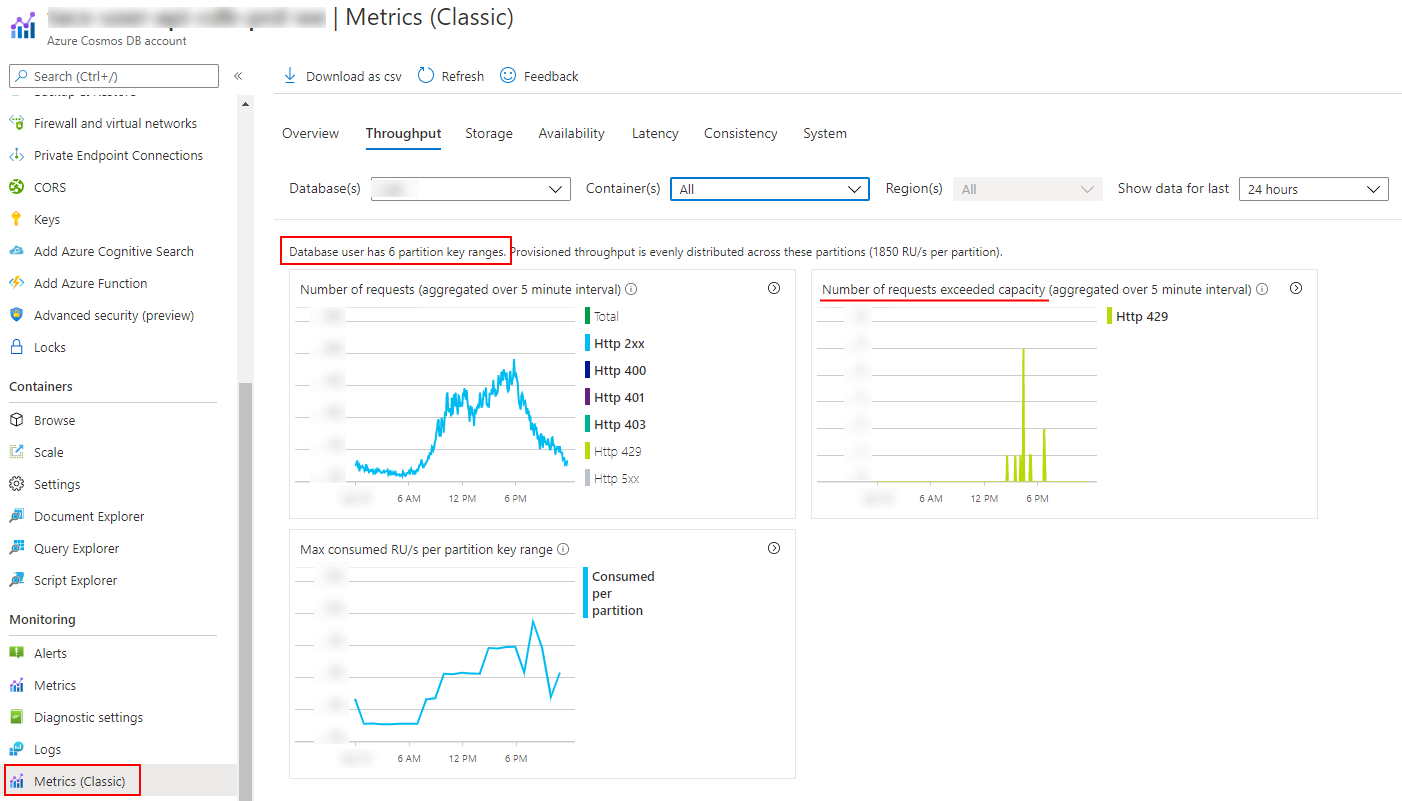
If you want to read more about the impact of partition splits is, I can recommend this blog post.
Query vs Point reads
The price you pay for Cosmos Db is based on the storage and RU capacity you need, and the RU capacity you need largely depends on how you access the database. In that sense it's interesting to see how many RU a certain operation consumes, and whether you can save costs by using point reads over queries.
So what's the difference between a query and a (point) read?
Every document stored in Cosmos Db needs to have a document ID, which uniquely identifies the document.
This document ID (together with the partition key) should be chosen in such a way that you can reconstruct it to retrieve a certain document.
Typically this is a unique value related to the data you store, for example a Customer Id, Order Id or other GUID-like value.
If you don't have such a key, then you can use synthetic values to create a unique document id which is easy to reconstruct when you need to access a document.
This can look like customerid_orderid_country for instance, it needs to be a unique string, that's all.
If you want to store multiple document types in the same container, you can for example decide to use documenttype_customerid.
Retrieving a document based on this document ID (or partition key) is called a point read and Cosmos Db is able to efficiently lookup and retrieve the document.
Retrieving a document based on a different field is called a quer and worst case Cosmos Db need to traverse the entire list of indexed fields to find the one matching the request.
As an example, the difference between query and point read from a RU point of view, as seen in the Data Explorer tool in the Azure portal. Left is a point read, right is a query, both on the same data set.
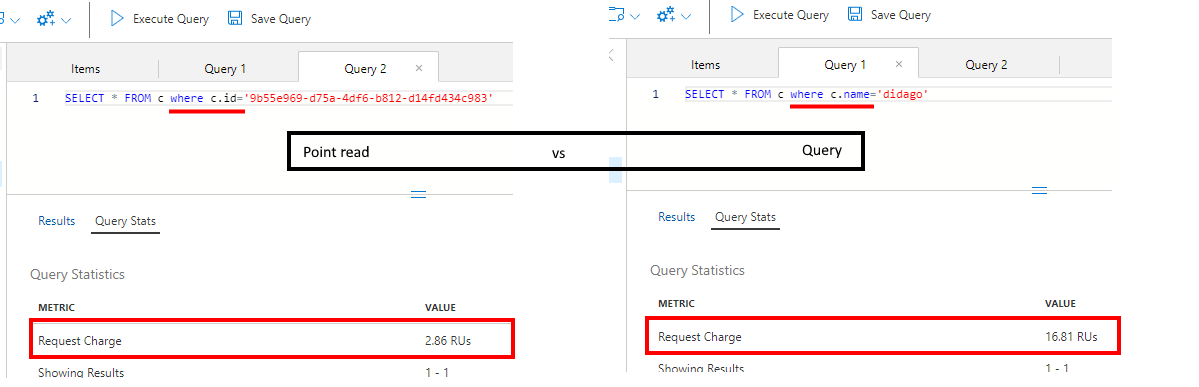
A point read is about 8 times more efficient than a query, or to put it differently, you can do with 8 times less capacity if you are able to use point reads instead of queries. Knowing capacity is expensive, this can mean a serious cost reduction.
If don't spend enough time on your document retrieval strategy, you might end up having capacity issues or pay an unnecessary large amount of money for you Cosmos Db instance. In the end it all comes down to the number of RU you need: RU = money
Monitoring
Now you know you should use point reads a much as possible, but how do you know whether you actually do use reads?
Fortunately there are metrics for this and the place to be is Azure Monitor.
Below a screenshot of the overview of the Cosmos Db instances running in a certain Azure subscription, showing the number of requests, data size and capacity consumption.
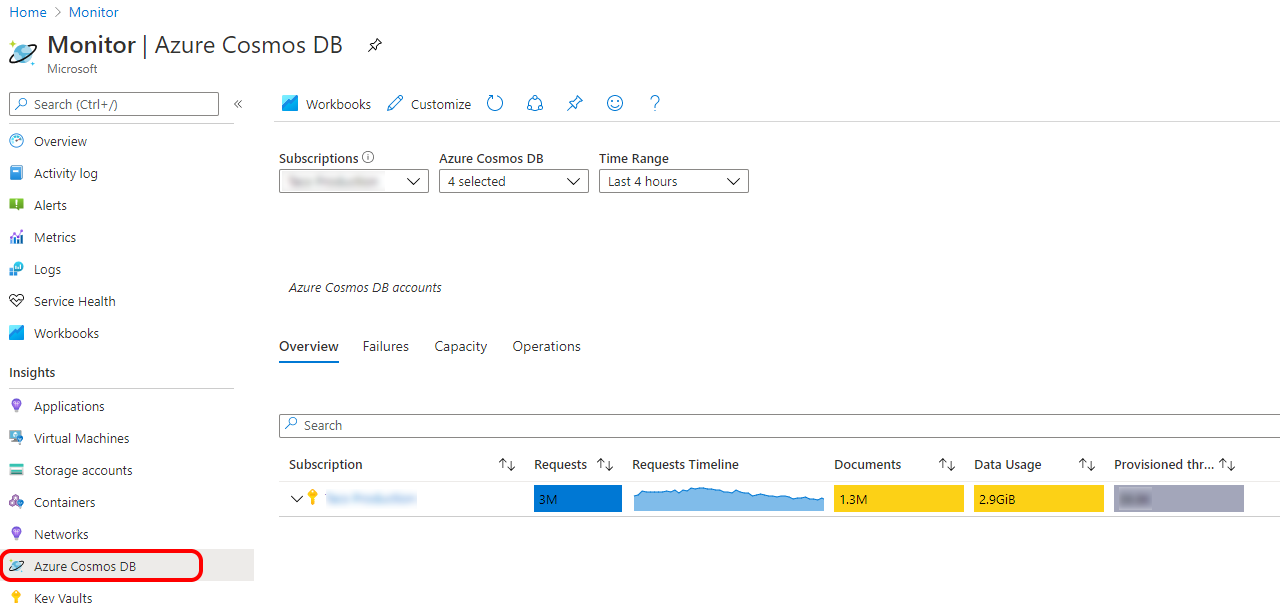
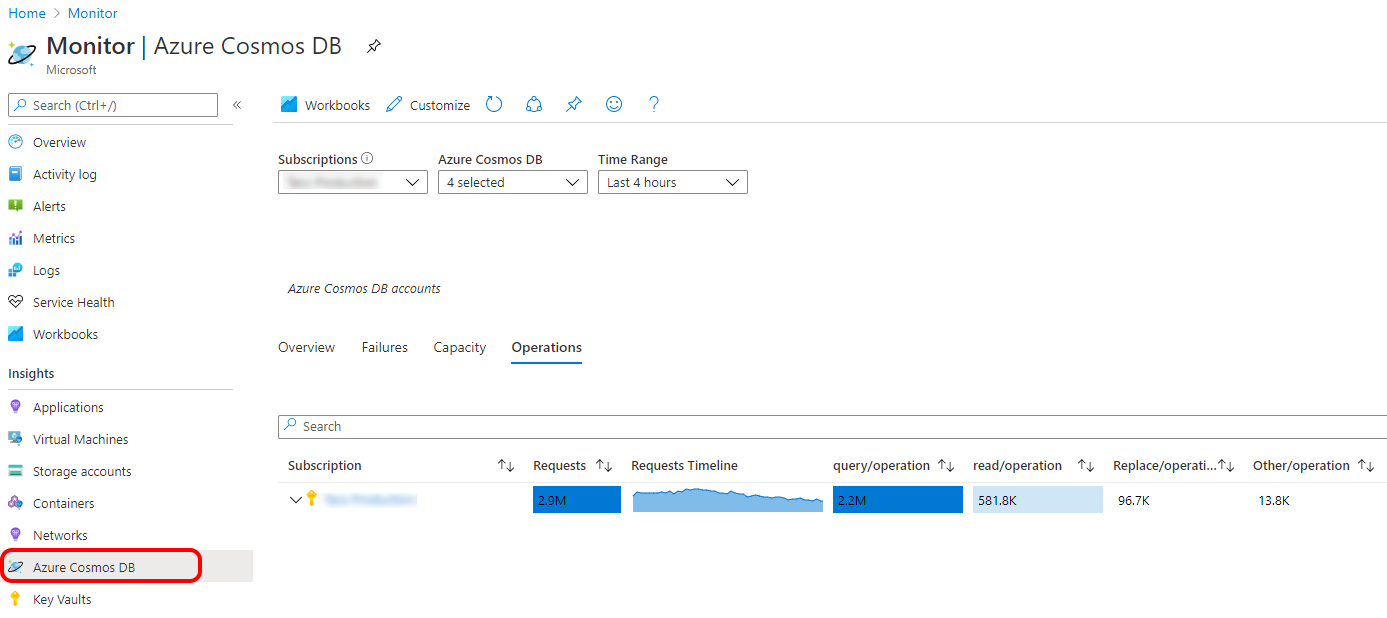
In the Cosmos Db operations section, you can find some information about operation types.
Although this is a nice overview, you like to see more details about the operations used by your code. For this you need to go to the metrics section and select “Total Requests” and split by “Operation” to show exactly what kind of operations are executed against your Cosmos Db instance.
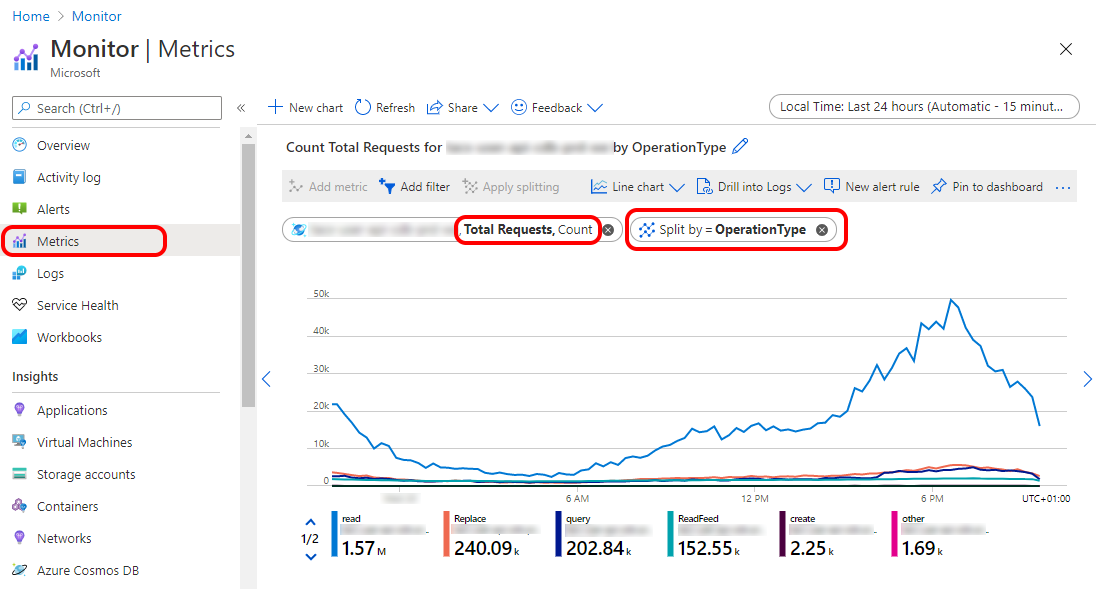
Having these metrics will help you with measuring whether a change in your code actually lead to less queries and more point reads. It's also intersting to see how many requests are done by the feed read, which is an Azure Function with a Cosmos Db binding, handling the change feed.
Final thoughts
There is a lot to take into account when designing a solution for Cosmos Db. Fortunately there is extensive documentation and guidance to be found, but it's important to test your approach with a production like load to be sure it behaves as expected.
In my search for information I came across this really interesting and helpful Integration Down Under video: https://youtu.be/VUjSePT0pzo
During our journey we discovered a couple of things while testing, but also learned a couple of lessons after go-live. Discussions with Microsoft lead to a better insight in how Cosmos Db behaves under certain circumstances and what the implications actually are of some of the documented characteristics. With this blog post I hope to give you some insights that will help you make the right decisions.
If you have any comments or remarks, you can reach me on Twitter @jeanpaulsmit.