Azure Event Grid is in many companies the backbone of their event driven architecture. When you have users from all over the world and cannot afford outage, then you need to design for high availability (HA). You can implement HA at many levels. From having multiple copies in a single data center all the way to copies across regions and even continents. The bigger the distance between the copies, the lower the risk of having an simultaneous outage due to for example a natural disaster. However, the backdraw of this distance is that it typically is harder to keep the copies aligend (for example regarding data).
For Event Grid we have the option to use out of the box solution or create our own.
Out of the box HA
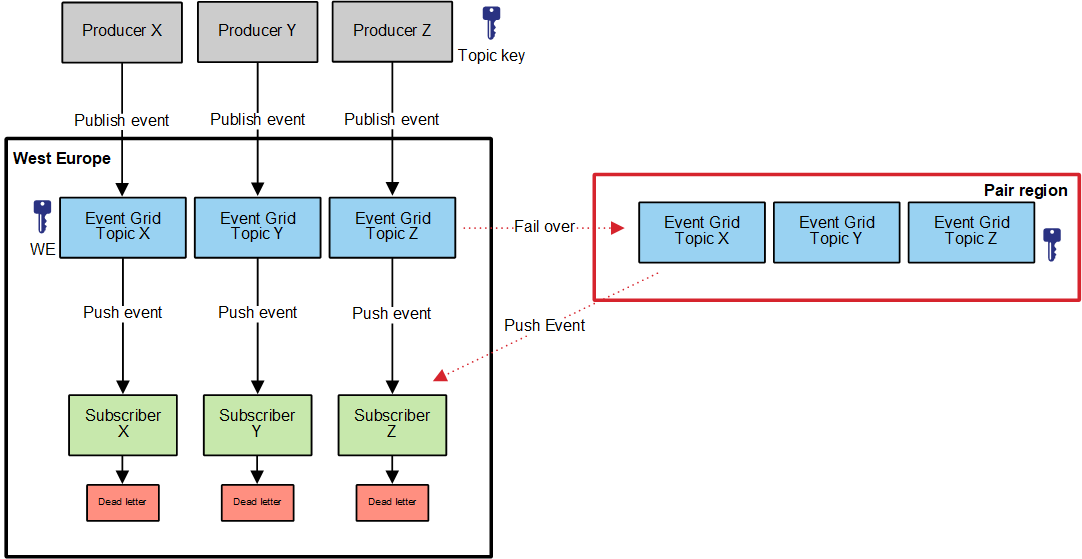
Looking at Event Grid (EG) we learn that this is setup as a SAAS solution, so you don't have to manage any resources but the Topic and Subscribers. Azure is taking care of managing the resources and scaling up and down depending on the demand.
Azure also supports out of the box disaster recovery mechnism. The topic infrastructure metadata (which also contains the subscribers) is being replicated to the pair region. This means that in case of an outage, there is supposed to a seemless fail-over to the pair region.
The DR article raises a couple of questions:
- If the topic moves to the pair region in case of a DR event, what is the impact on the event publishers using a URL to publish the events?
- Is there some way to customize the pair region? What if I already use certain regions?
- How certain can I be the event handlers (subscribers) will be able to process the event? After all, there appears to be an outage severe enough to fail over Event Grid to the pair region. My subscribers might also not be available anymore?
Regarding event publishers, there could be impact. The URL you use to publish events to a topic, contains the region. The format is [topic-name].[region]-1.azure.net/api/events.
For example: https://didago-topic.westeurope-1.eventgrid.azure.net/api/events
Fortunately Microsoft confirmed that the URL of the topic remains the same after a fail-over to the pair region, so publishers won't notice any difference before or after the fail-over.
The fail-over region is the pair region of the primary and that cannot be changed to a custom region. In all honesty, the risk of having both the primary region and pair region down at the same time is very unlikely. In case of such an event, something really serious has happened either to Microsoft or the continent the region lives in. I suspect the main reason for Microsoft to pick the pair region to fail-over to, is because this minimizes the latency and the risk of having a topic created in the primary region just before the calamity so it couldn't be replicated to the pair region in time.
The point about HA and subscribers is not solved by the out of the box solution. The EG infrastructure is copied, but the subscriber still is only in the same (single) location. From an EG point of view this solution is HA, but from the subscribers point of view things are not. If the subscriber is down in the deployed region, the events are lost (unless you configure a dead letter queue on the subscription).
Optimized out of the box HA
With a rather small change we can improve the HA characteristics of the previous solution. The bottleneck is the fact that the subscribers are not HA. To solve this we need to deploy the subscriber event handlers to separate regions and have events pushed to either one of the regions via a load balancer. And if we combine this with API Management, we have a flexible solution where subscribers also are HA.
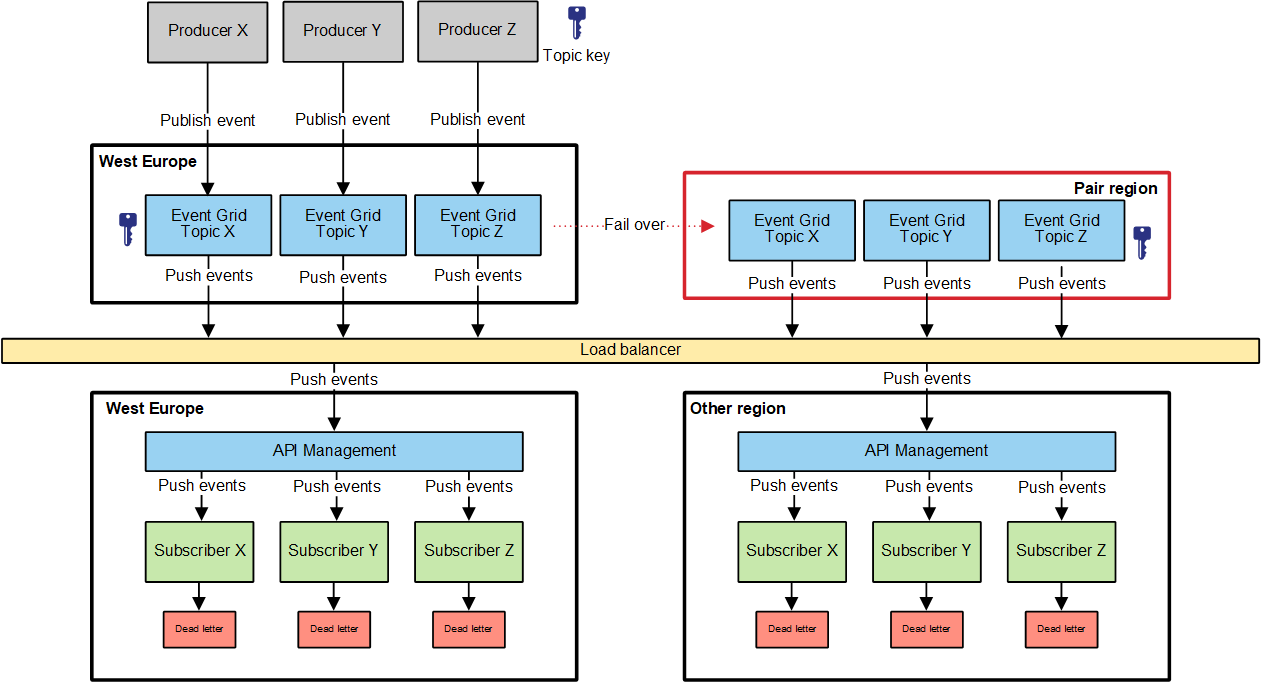
When we have the endpoint URL of API Management configured on the subscriber, the event will be pushed to whatever region is available in case of a fail-over.
Fully custom HA
The most extensive solution is a fully custom solution in which you manage the fail-over yourself.
This means creating a secondary topic in a different region, and put a load balancer and API Management in front to determine to which region to send the event to. Actually this is not a secondary topic but a second primary topic, as the load balancer treats both regions the same way.
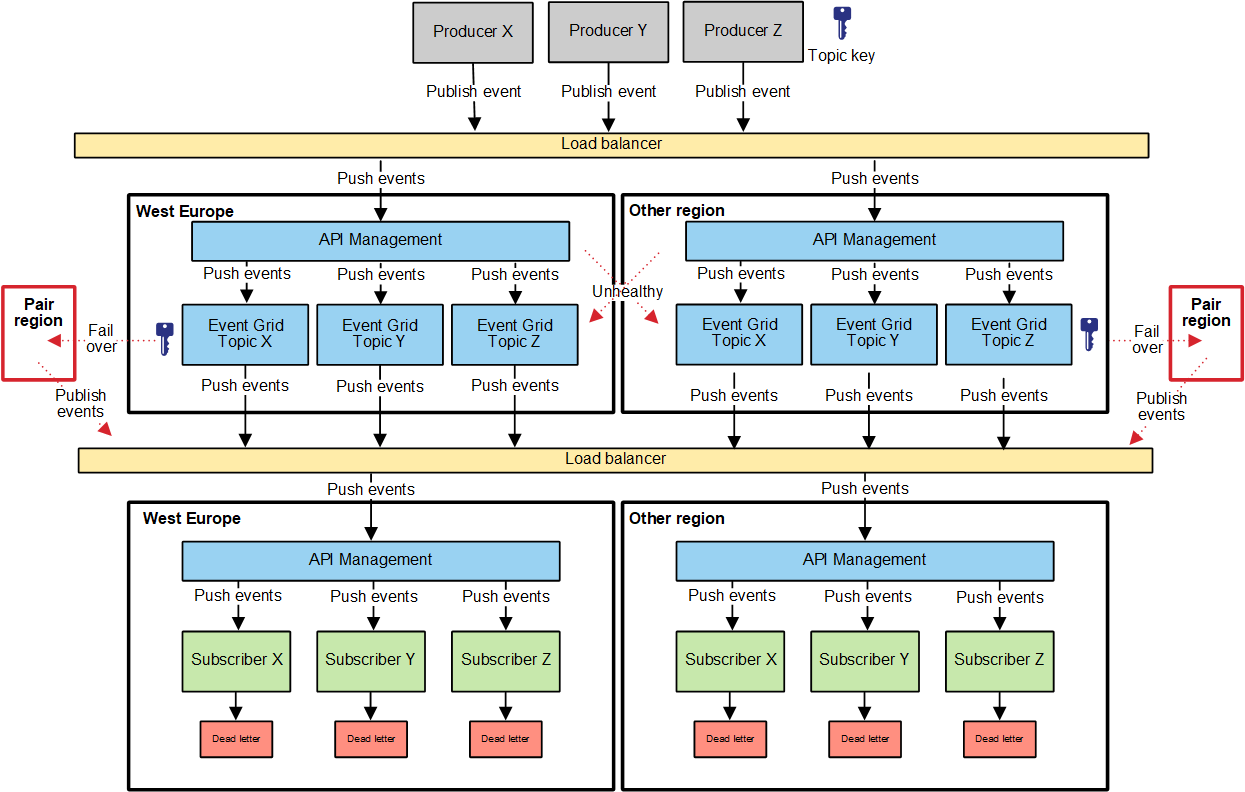
This solution provides the most flexibility, but there are a couple of things to keep in mind.
First of all, this actually is a double HA solution. Having a custom solution in place, doesn't mean the out of the box HA doesn't work anymore. It's not something you can disable or switch it off, you get it whether you like (or need it) or not. This means that this solution approach still works when even the primary fail-over pair region AND the second primary region is down.
But, how do you know the fail-over pair region is down? You don't want the load balancer or APIM to send events to a region, where the topic there is unavailable. The caller will get an error in that case, while the other region still might be able to process the events.
You can determine whether a topic is available, by calling GET /api/health endpoint on that topic. When healthy, it will return HTTP 200, so you know the event can be safely publish to the topic. Checking of this health endpoint needs to be done in an APIM policy, where first a call to the health endpoint will be done before sending the event to the topic. In case the topic in that region is not healthy, the request is forwarded to the other region. Having a policy doing a check like that, has a maintenance and performance impact. With a low number of events you won't notice a difference, but with millions of events it might become an issue. Of course you can cache the result from the health check to perform it only every so many seconds/minutes, but still there is a performance hit. Another risk of caching this information for too long, is events can get lost if in between cache refreshes the topic becomes unavailable. This client side fail-over from a publisher point of view is documented by Microsoft here.
Also you have to think about topic key management. In order to be able to publish an event to a topic, you need provide a topic key as HTTP header (aeg-sas-key). Each topic is a separate Azure resource with a separate topic key which is generated on creation and cannot be customized. As the event publisher cannot know in which region the request ends up, it cannot provide the correct topic key. A solution for this is to generate a topic key yourself, and provide that in the call to the event publisher in APIM. In the APIM policy for the topic you then convert the incoming custom topic key into the topic key generated for that region.
Closing note
As you can see there are several options for designing a high available solution with Event Grid.
In the end it depends on your requirements, but the fully custom solution might be a bit too much most of the time.
As Eveng Grid already has a quite nice out of the box solution for HA, my default option would be the second one where we utilized the out of the box features while still having HA for subscribers.
For gettting more information on this topic, I created a question on SO earlier. The Event Grid PM from Microsoft (Javier Fernandez) replied. If you have anything to add, have a different solution or approach, it would be great if you could add it as answer or comment there.
If you have any questions, you can always reach out to me on Twitter.