There are many blogs discussing API versioning, but most of them focus on the way it is visible to API consumers.
Regarding that, in the end it all boils down a kind of to personal preference and you'll end up with either:
- URL versioning (https://api.company.com/v1/controller or https://api-v1.company.com/controller)
- Query string versioning (https://api.company.com/controller?version=v1)
- HTTP Header versioning (api-version: v1)
You can find a recent blog about this here.
However, I'd like to focus on what you want to achieve with versioning and what that means for your code and deployment strategy.
Why versioning?
The main reason for versioning is to be able to provide consumers with a reliable and stable API interface they can consume. Consumers might depend on a certain API version providing certain functionality, so you cannot just change that interface as it would break consumers.
In some cases consumers even depend on known bugs in your code! They handle this on their side, suddenly fixing it could mean it also breaks their code. This is (I hope) a fairly exceptional case and typically you can safely fix bugs when it doesn't change the API interface, but it indicates how far consumers can in depending on a version.
To prevent angry customers, versioning provides you a way to leave existing functionality untouched, while creating and publishing a new version with new functionality and possible bug fixes.
But what does that exactly mean? What is the impact on your way of working if you apply a certain approach?
We have a roughly two ways to approach versioning.
Single codebase
This is the most used way to implement versioning, just put everything in the same project.
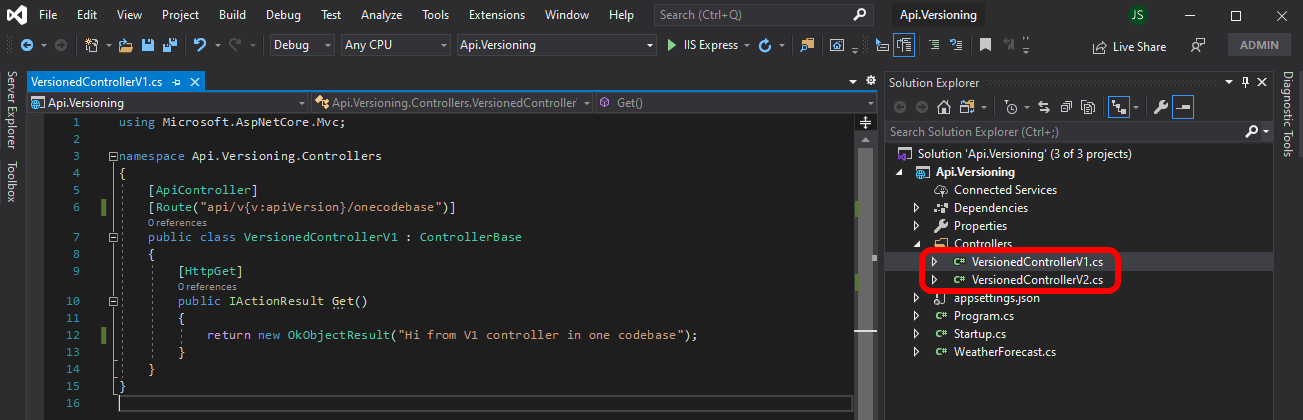
This is very convenient from a developer point of view:
- all related code is in the same project
- different versions can easily use the same shared code
- deployment is the same for all versions
And it does make sense to have the code for all versions in the same project, as different versions all are related and mainly differ in interface and extended functionality in the same domain. It is very common to have different versions on API level, but behind the scenes they use the same services and code to do the actual work.
However, it also violates one of the main reasons behind versioning: providing consumers a reliable and stable API interface.
- individual versions are not isolated from changes
- a change in version x might introduce a bug in version y
- a change in shared code can impact a version you didn't mean to touch
- deployment of a new version requires downtime of all versions, this can be mitigated by utilizing deployment slots, but every time you deploy the entire set of versions regardless whether they've been changed or not
Deployment
From a deployment perspective one codebase is not only easier but also cheaper. After all you only need one set of resources to host the API. From an Azure perspective this would mean just one App Service Plan and one App Service (with deployment slots for zero downtime deployments). Multiple versions can be run on the same App Service Plan. Also there is only need for one build and release pipeline.
The main deployment disadvantages of this approach are:
- downtime for all versions when only one version is updated (mitigated by using deployment slots)
- not able to scale per version: when one version is heaviliy used and requires scale out, all versions will be scaled out
Separate code bases
When you want to fully control the versions of the API you have, separated code bases are the way to go.
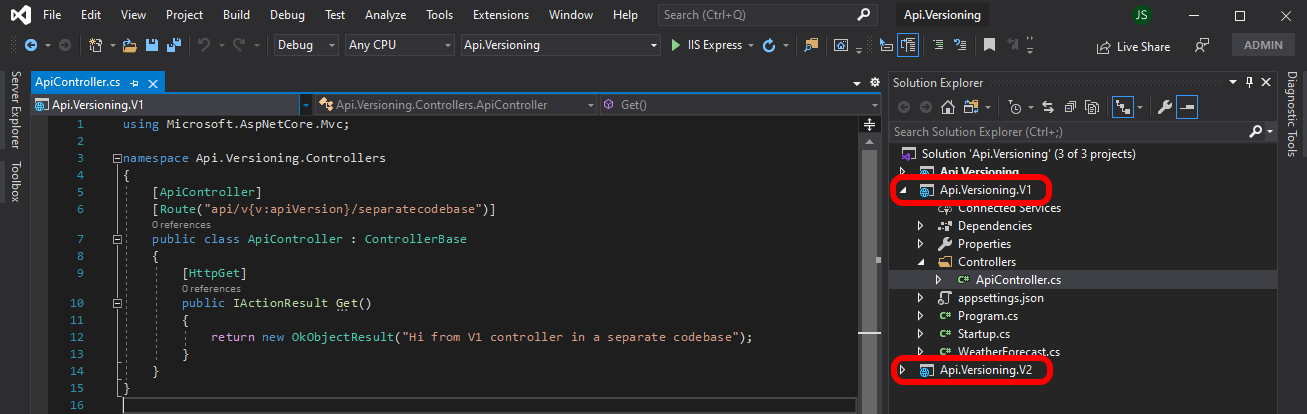
Main characteristics:
- every version of the API has it's own project
- more work in sharing code, but possible via Nuget packages
- fully isolated deployment
A new API version is most of the time an extension of an existing one, so your first though might be to just copy the existing one and proceed from there. Although the code base is fully isolated, you also end up with a lot of duplicate code. Having to fix a bug in such a piece of code, would mean you have to make the change to all versions you copied the code from (unless consumers depend on the bug to be there).
The moment you start copying code, you should get an uncomfortable feeling. Code duplication almost never is a good idea, so make sure you move that shared code into a Nuget library for all versions to use. This might involve refactoring of the existing version to use that Nuget package, which ironically is a risk as you touch an existing version you didn't want to touch….
When you have a solid unit and integration test strategy, you'll probably feel comfortable with making these changes.
One other thing to keep in mind is that you need to keep track of the versions when you have separate codebases. Projects are entirely independend of each other, so the version configuration should be specified separately also. It's easy to forget to increase the version number after copying the previous version.
Deployment
This is the part where you really have the advantage of separate code bases. You'll have a build and release pipeline for each of your versions, making it absolutely safe to deploy a certain version. Disadvantae is you do need to manage and maintain a seperate CI/CD pipeline for each of the versions.
The separate codebase solution is more expensive in Azure resources, as it makes sense when you pick this solution to have each version in their own App Service Plan, or even in a separate resource group. It provides tremendous flexibility regarding scalability without the risk interfering with existing versions.
Conclusion
What is the best approach? This depends on your requirements.
The most simple and cheapest way to implement versioning, is to have everything in the same project. If you start with versioning this would be the approach to start with.
The separate codebase solution is more expensive in any way you look at it. More code to maintain, more work to implement and more Azure resources to consume. It does provide distinct advantages but I have not yet run into customer using this approach for their API's.
Do you have any experience with versioning using seperate codebases? Or do you use a different approach? I'd love to hear from you! Please contact me on Twitter.